Hm, irgendwie scheint die neue Forensoftware noch ihre Probleme zu haben, deine Bildchen sind nicht da.
Bei mir wurden sie angezeigt -.- Hab mal 2 Dinge versucht, um es zu fixen. Könnt ja mal Feedback geben, wieviele Bilder und wieviele Links auf die BIlder nun bei euch angezeigt werden...
n:m ist in der Tat ungünstig. Wenn die Bilder da sind, kann ich dir vielleicht helfen.
Ich hoffe, jetzt gehts...
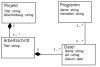
Du gibst also ProjectView die Daten in Form des Entitäts-Objektes Project und läßt ProjectView damit arbeiten. Also alles in Butter
")
Nun hat dieses Entitäts-Objekt ja einen Container mit "Arbeitschritten", von denen jeder wiederum einen Container mit "Dateien" hat. Wenn du also nichts an meinem Klassen-Diagram änderst, würde ich mich freuen, wenn du einen kleinen Pseudecode o.ä. skizzieren könntest, wie du ohne Getter auf die Datei 1 im Arbeitschritt 1 zugreifen willst!? *ratlos* Mein Pseudocode sähe vllt. so aus:
Code:
// wir befinden uns in ProjectView. ProjektView hat ein privates Attribute "private Projekt projekt"
Collection temp = projekt.getArbeitschritte().getDateien();
Datei datei1 = erstes Element von temp;
edit: Interessant wäre vllt. auch mal, wie man Entitäts-Objekt eigentlich konkret definiert? Ich verstehe darunter eine Klasse, die nur Attribute und getter-Methoden beinhaltet (da public-Attribute ja böse sind)!?
[Warum beschleicht mich gerade das Gefühl, dass ich blutiger Anfänger mit 0 Ahnung bin...]
Hmmm.. also K-V-Stores haben bei mir nur wenig mit XML zutun.
Key-Value Store hatte ich in Wiki direkt nicht gefunden und nahm daher an, dass Dokumentenorientierte Datenbanken dasselbe seihen (die hab ich nämlich auf der suche nach Key-Value-Stores gefunden), wobei ich mittlerweile glaub, dass ich auch Dokumentenorientierte Datenbanken falsch verstanden hatte, weil die ja nicht auf
einem, sondern
mehreren Dokumenten basieren... Damit erscheinen sie für Dateiverwaltung (um die es im Beispiel ja irgendwie letztendlich geht) prinzipiell geeigneter, allerdings weiß ich immernoch nicht, wie das modell dazu aussähe...
Wenn ich es mittlerweile richtig verstehe, wären K-V-Stores sowas ähnliches wie NSDictionary (oder auch HashTable/HashMap in Java), die Dokumentorientierten Datenbanken dagegen sind sowas wie CFBundle (bzw. jar-Dateien)?
Beispiel: Das hier wäre beispielsweise eine dokumentbasierte Datenbank?
Code:
Projekte
|---Projekt 1
|---info.xml
|---Arbeitsschritte
|---Arbeitsschritt 1
| |---Datei 1
|---Arbeitsschritt 2
|---Datei 2
usw.
in info.xml stünden Projektinfos (Titel, beschreibung) und die korrekte Reihenfolge der Arbeitschritte. Die "Datenbank" wäre dann also die Funktionen, die mir z.B. Datei 2 ausgeben, wenn ich nach der aktuellsten Datei im Projekt 1 fragen, richtig?
Big Table ist im endeffekt nur die Normalisierung einer relationalen DB auf eine einzige Tabelle. Du hast für einen Datensatz nicht mehr N zugriffe (auf die zum Datensatz gehörenen M Tabellen, M >= N), sondern nur noch einen Zugriff, um die gewünschten Zeilen aus der DB zu holen.
Oje... wenn ich mir mein Beispiel mit den Tabellen anschaue (siehe Bild oben), frage ich mich spontan wie das gehen soll... aber da werden BigTables wohl techniken für haben. kann ich mir bei gelegenheit mal anschauen.
Was verstehst du eigentlich unter einer Beziehungstabelle?
Im Tabellen-Bild (s.o.) die Tabellen mit der grauen "Titelleiste". Prinzipiell nichts anderes, was du auch sagstest (mit Foreign Keys). Das klassischere Beispiel wäre ein Shop System, das eine Tabelle mit Artikeln und eine mit Kunden hätte. Für die Rechnungen gibts dann z.B. eine Beziehungstabelle:
Tabelle "Rechnungen"
KundenID | ArtikelID | RechnungDatum | Preis
Wobei... mh... dann braucht man den Begriff "Beziehungstabelle" echt nicht, weil Beziehungstabellen
nicht ausschließlich Foreign Keys beinhalten müssen.
Gruß Micha